Tip
Update a Wflow model: landuse#
Once you have a Wflow model, you may want to update your model in order to use a new landuse map, change a parameter value, add sample locations, use different forcing data, create and run different scenarios etc.
With HydroMT, you can easily read your model and update one or several components of your model using the update function of the command line interface (CLI). Here are the steps and some examples on how to update the landuse map and parameters.
All lines in this notebook which starts with ! are executed from the command line. Within the notebook environment the logging messages are shown after completion. You can also copy these lines and paste them in your shell to get more direct feedback.
Import packages#
In this notebook, we will use some functions of HydroMT to check available datasets and also to plot the landuse maps from the original and updated models. Here are the libraries to import to realize these steps.
[1]:
import numpy as np
import pandas as pd
import hydromt
from hydromt_wflow import WflowSbmModel
from hydromt import log
# Configure logging
log.initialize_logging()
# for plotting
import matplotlib as mpl
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
proj = ccrs.PlateCarree() # plot projection
2026-07-30 09:42:33,276 - hydromt - log - INFO - HydroMT version: 1.4.0
Searching the data catalog for landuse#
In our previous notebook, we built a Wflow model using the GlobCover landuse classification. But we could as well have chosen another one. Let’s what other landuse landcover data are available in HydroMT and choose another landuse classification for our model. For this we will open the data catalog.
You can also directly open and search the HydroMT yaml library by downloading and opening the data_catalog.yml file in hydromt-artifacts or look at the list of data sources in the documentation.
[2]:
# Load the default data catalog of HydroMT
data_catalog = hydromt.DataCatalog("artifact_data")
2026-07-30 09:42:33,592 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Reading data catalog artifact_data latest
2026-07-30 09:42:33,593 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt/artifact_data/v1.0.0/data_catalog.yml
[3]:
# Check which landuse/lancover sources are available in the DataCatalog
data_table = data_catalog._to_dataframe()
data_table[data_table["category"] == "landuse & landcover"]
[3]:
| provider | version | uri | data_type | driver | crs | category | paper_doi | paper_ref | url | license | author | unit | history | notes | nodata | info | processing_notes | timestamp | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| name | |||||||||||||||||||
| corine | None | v.2020_20u1 | corine.tif | RasterDataset | RasterioDriver | NaN | landuse & landcover | NaN | NaN | https://land.copernicus.eu/pan-european/corine... | https://land.copernicus.eu/pan-european/corine... | European Environment Agency | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| globcover_2009 | None | None | globcover.tif | RasterDataset | RasterioDriver | 4326 | landuse & landcover | 10.1594/PANGAEA.787668 | Arino et al (2012) | http://due.esrin.esa.int/page_globcover.php | CC-BY-3.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| modis_lai | None | 6 | modis_lai.nc | RasterDataset | RasterDatasetXarrayDriver | 4326 | landuse & landcover | 10.5067/MODIS/MCD15A3H.006 | Myneni et al (2015) | https://lpdaac.usgs.gov/products/mcd15a3hv006/ | https://lpdaac.usgs.gov/data/data-citation-and... | NaN | NaN | NaN | this dataset has been extracted from GEE ('MOD... | NaN | NaN | NaN | NaN |
| simard | None | None | simard.tif | RasterDataset | RasterioDriver | 4326 | landuse & landcover | 10.1029/2011JG001708 | Simard et al (2011) | https://webmap.ornl.gov/ogc/dataset.jsp?ds_id=... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| vito_2015 | None | 2.0.2 | vito.tif | RasterDataset | RasterioDriver | 4326 | landuse & landcover | 10.5281/zenodo.3939038 | Buchhorn et al (2020) | https://land.copernicus.eu/global/products/lc | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Here we can see that we have five data sources in HydroMT related to landuse & landcover properties. Out of these, three are landuse classifications:
globcover_2009 (already used in our current model)
corine
vito_2015
The other datasets include a Leaf Area Index dataset (modis_lai) and a canopy height dataset (simard).
Let’s now see how to update our current model in one command line to use the corine classification.
HydroMT CLI update interface#
Using the HydroMT build API, we can update one or several components of an already existing Wflow model. Let’s get an overview of the available options:
[4]:
# Print the options available from the update command
! hydromt update --help
Usage: hydromt update [OPTIONS] MODEL MODEL_ROOT
Update a specific component of a model.
Set an output directory to copy the edited model to a new folder, otherwise
maps are overwritten.
Example usage: --------------
Update Wflow model components outlined in an .yml configuration file and
write the model to a directory: hydromt update wflow_sbm /path/to/model_root
-o /path/to/model_out -i /path/to/wflow_config.yml -d
/path/to/data_catalog.yml -v
Options:
-o, --model-out DIRECTORY Output model folder. Maps in MODEL_ROOT are
overwritten if left empty.
-i, --config PATH Path to hydroMT configuration file, for the model
specific implementation. [required]
-d, --data TEXT Path to local yaml data catalog file OR name of
predefined data catalog.
--dd, --deltares-data Flag: Shortcut to add the "deltares_data" catalog
--fo, --force-overwrite Flag: If provided overwrite existing model files
--cache Flag: If provided cache tiled rasterdatasets
-q, --quiet Decrease verbosity.
-v, --verbose Increase verbosity.
--help Show this message and exit.
Model setup configuration#
To let HydroMT know which setup method to call and the options, you can prepare and use a configuration file that includes every methods and settings that you want to do during your update.
The HydroMT configuration file (YAML) contains the model setup configuration and determines which methods are updated and in which sequence and sets optional arguments for each method. This configuration is passed to hydromt using -i <path_to_config_file>.
Each header (without indent) (e.g. setup_lulcmaps:) corresponds with a model method which are explained in the docs (model methods).
Let’s open the example configuration file wflow_update_landuse.yml from the model repository [examples folder] and have a look at the settings.
[5]:
fn_config = "wflow_update_landuse.yml"
with open(fn_config, "r") as f:
txt = f.read()
print(txt)
steps:
- setup_lulcmaps:
lulc_fn : corine # source for lulc maps: {globcover, vito, corine}
lulc_mapping_fn: corine_mapping_default # default mapping for lulc classes
output_names_suffix: corine # add a suffix to the output map names in staticmaps rather than overwriting existing landuse maps
Here we can see that to fully update wflow forcing, we will run one methods of Wflow:
setup_lulcmaps: prepares landuse map and parameters based on a landuse map
lulc_fnand a mapping tablelulc_mapping_fnto convert from specific landuse classes (urban, forest) to hydrological parameters (roughness, depth of the vegetation roots etc).
Here, we can see that we will update the landuse with the classification from CORINE and using the HydroMT default mapping table for the parameter creation (HydroMT supports a few of these including “globcover”, “corine”, “vito” and “esa_worldcover”). If you want to use a different classification or update the default values (eg for calibration), you can create and catalog your own table.
We will also here save the different maps with the suffix “corine” via the output_names_suffix options. If this option is not provided (or None), the new maps will overwrite previously existing ones. Here we will keep both the globcover maps and the new maps from CORINE in the updated model.
You can find more information about the different options in the docs (setup lulcmaps)
Update Wflow landuse layers#
Copy this line to your shell for more direct feedback:
hydromt update wflow_sbm wflow_piave_subbasin -o ./wflow_piave_corine -i wflow_update_landuse.yml -d artifact_data -v
[6]:
# In the jupyter notebook we call hydromt through python to ensure errors are raised in the notebook instead of in a subprocess.
from hydromt.cli import main
main.update(args=["wflow_sbm", "wflow_piave_subbasin", "-o", "./wflow_piave_corine", "-i", "wflow_update_landuse.yml", "-d", "artifact_data", "-v"], standalone_mode=False)
2026-07-30 09:42:37,176 - hydromt - log - INFO - HydroMT version: 1.4.0
2026-07-30 09:42:37,176 - hydromt - log - INFO - HydroMT version: 1.4.0
2026-07-30 09:42:37,202 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Reading data catalog artifact_data latest
2026-07-30 09:42:37,202 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Reading data catalog artifact_data latest
2026-07-30 09:42:37,203 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt/artifact_data/v1.0.0/data_catalog.yml
2026-07-30 09:42:37,203 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt/artifact_data/v1.0.0/data_catalog.yml
2026-07-30 09:42:37,794 - hydromt.model.model - model - INFO - Initializing wflow_sbm model from hydromt_wflow (v1.0.3.dev0).
2026-07-30 09:42:37,794 - hydromt.model.model - model - INFO - Initializing wflow_sbm model from hydromt_wflow (v1.0.3.dev0).
2026-07-30 09:42:37,795 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/parameters_data.yml
2026-07-30 09:42:37,795 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/parameters_data.yml
2026-07-30 09:42:37,811 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_subbasin/wflow_sbm.toml.
2026-07-30 09:42:37,811 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_subbasin/wflow_sbm.toml.
2026-07-30 09:42:37,813 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Supported Wflow.jl version v1.1.
2026-07-30 09:42:37,813 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Supported Wflow.jl version v1.1.
2026-07-30 09:42:37,815 - hydromt - log - INFO - HydroMT version: 1.4.0
2026-07-30 09:42:37,815 - hydromt - log - INFO - HydroMT version: 1.4.0
2026-07-30 09:42:37,816 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_subbasin/wflow_sbm.toml.
2026-07-30 09:42:37,816 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_subbasin/wflow_sbm.toml.
2026-07-30 09:42:38,369 - hydromt.hydromt_wflow.components.tables - tables - INFO - Reading model table files.
2026-07-30 09:42:38,369 - hydromt.hydromt_wflow.components.tables - tables - INFO - Reading model table files.
2026-07-30 09:42:38,373 - hydromt.model.model - model - INFO - update: setup_lulcmaps
2026-07-30 09:42:38,373 - hydromt.model.model - model - INFO - update: setup_lulcmaps
2026-07-30 09:42:38,374 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_mapping_fn=corine_mapping_default
2026-07-30 09:42:38,374 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_mapping_fn=corine_mapping_default
2026-07-30 09:42:38,375 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_vars=['landuse', 'vegetation_kext', 'land_manning_n', 'soil_compacted_fraction', 'vegetation_root_depth', 'vegetation_leaf_storage', 'vegetation_wood_storage', 'land_water_fraction', 'vegetation_crop_factor', 'vegetation_feddes_alpha_h1', 'vegetation_feddes_h1', 'vegetation_feddes_h2', 'vegetation_feddes_h3_high', 'vegetation_feddes_h3_low', 'vegetation_feddes_h4']
2026-07-30 09:42:38,375 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_vars=['landuse', 'vegetation_kext', 'land_manning_n', 'soil_compacted_fraction', 'vegetation_root_depth', 'vegetation_leaf_storage', 'vegetation_wood_storage', 'land_water_fraction', 'vegetation_crop_factor', 'vegetation_feddes_alpha_h1', 'vegetation_feddes_h1', 'vegetation_feddes_h2', 'vegetation_feddes_h3_high', 'vegetation_feddes_h3_low', 'vegetation_feddes_h4']
2026-07-30 09:42:38,375 - hydromt.model.model - model - INFO - setup_lulcmaps.output_names_suffix=corine
2026-07-30 09:42:38,375 - hydromt.model.model - model - INFO - setup_lulcmaps.output_names_suffix=corine
2026-07-30 09:42:38,376 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_fn=corine
2026-07-30 09:42:38,376 - hydromt.model.model - model - INFO - setup_lulcmaps.lulc_fn=corine
2026-07-30 09:42:38,377 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Preparing LULC parameter maps.
2026-07-30 09:42:38,377 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Preparing LULC parameter maps.
2026-07-30 09:42:38,380 - hydromt.data_catalog.sources.data_source - data_source - INFO - Reading corine RasterDataset data from /home/runner/.hydromt/artifact_data/latest/corine.tif
2026-07-30 09:42:38,380 - hydromt.data_catalog.sources.data_source - data_source - INFO - Reading corine RasterDataset data from /home/runner/.hydromt/artifact_data/latest/corine.tif
2026-07-30 09:42:38,427 - hydromt.data_catalog.sources.data_source - data_source - INFO - Reading corine_mapping_default DataFrame data from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/lulc/v1.0/corine_mapping.csv
2026-07-30 09:42:38,427 - hydromt.data_catalog.sources.data_source - data_source - INFO - Reading corine_mapping_default DataFrame data from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/lulc/v1.0/corine_mapping.csv
2026-07-30 09:42:38,439 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving landuse using mode resampling (nodata=999).
2026-07-30 09:42:38,439 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving landuse using mode resampling (nodata=999).
2026-07-30 09:42:39,245 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_kext using average resampling (nodata=-999.0).
2026-07-30 09:42:39,245 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_kext using average resampling (nodata=-999.0).
2026-07-30 09:42:39,372 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving land_manning_n using average resampling (nodata=-999.0).
2026-07-30 09:42:39,372 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving land_manning_n using average resampling (nodata=-999.0).
2026-07-30 09:42:39,496 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving soil_compacted_fraction using average resampling (nodata=-999.0).
2026-07-30 09:42:39,496 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving soil_compacted_fraction using average resampling (nodata=-999.0).
2026-07-30 09:42:39,620 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_root_depth using average resampling (nodata=-999.0).
2026-07-30 09:42:39,620 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_root_depth using average resampling (nodata=-999.0).
2026-07-30 09:42:39,746 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_leaf_storage using average resampling (nodata=-999.0).
2026-07-30 09:42:39,746 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_leaf_storage using average resampling (nodata=-999.0).
2026-07-30 09:42:39,870 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_wood_storage using average resampling (nodata=-999.0).
2026-07-30 09:42:39,870 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_wood_storage using average resampling (nodata=-999.0).
2026-07-30 09:42:39,995 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving land_water_fraction using average resampling (nodata=-999.0).
2026-07-30 09:42:39,995 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving land_water_fraction using average resampling (nodata=-999.0).
2026-07-30 09:42:40,121 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_crop_factor using average resampling (nodata=-999.0).
2026-07-30 09:42:40,121 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_crop_factor using average resampling (nodata=-999.0).
2026-07-30 09:42:40,247 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_alpha_h1 using mode resampling (nodata=-999).
2026-07-30 09:42:40,247 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_alpha_h1 using mode resampling (nodata=-999).
2026-07-30 09:42:40,398 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h1 using average resampling (nodata=-999).
2026-07-30 09:42:40,398 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h1 using average resampling (nodata=-999).
2026-07-30 09:42:40,536 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h2 using average resampling (nodata=-999).
2026-07-30 09:42:40,536 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h2 using average resampling (nodata=-999).
2026-07-30 09:42:40,680 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h3_high using average resampling (nodata=-999).
2026-07-30 09:42:40,680 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h3_high using average resampling (nodata=-999).
2026-07-30 09:42:40,824 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h3_low using average resampling (nodata=-999).
2026-07-30 09:42:40,824 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h3_low using average resampling (nodata=-999).
2026-07-30 09:42:40,970 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h4 using average resampling (nodata=-999).
2026-07-30 09:42:40,970 - hydromt.hydromt_wflow.workflows.landuse - landuse - INFO - Deriving vegetation_feddes_h4 using average resampling (nodata=-999).
2026-07-30 09:42:41,152 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Write model data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine
2026-07-30 09:42:41,152 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Write model data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine
2026-07-30 09:42:41,156 - hydromt.model.components.grid - grid - INFO - wflow_sbm.staticmaps: Writing grid data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticmaps.nc.
2026-07-30 09:42:41,156 - hydromt.model.components.grid - grid - INFO - wflow_sbm.staticmaps: Writing grid data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticmaps.nc.
2026-07-30 09:42:41,227 - hydromt.model.components.spatial - spatial - INFO - wflow_sbm.staticmaps: Writing region to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/region.geojson.
2026-07-30 09:42:41,227 - hydromt.model.components.spatial - spatial - INFO - wflow_sbm.staticmaps: Writing region to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/region.geojson.
2026-07-30 09:42:41,237 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_reservoirs_simple_control.geojson.
2026-07-30 09:42:41,237 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_reservoirs_simple_control.geojson.
2026-07-30 09:42:41,243 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/outlets.geojson.
2026-07-30 09:42:41,243 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/outlets.geojson.
2026-07-30 09:42:41,246 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/gauges_grdc.geojson.
2026-07-30 09:42:41,246 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/gauges_grdc.geojson.
2026-07-30 09:42:41,250 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/rivers.geojson.
2026-07-30 09:42:41,250 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/rivers.geojson.
2026-07-30 09:42:41,254 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_basins_highres.geojson.
2026-07-30 09:42:41,254 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_basins_highres.geojson.
2026-07-30 09:42:41,272 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/basins.geojson.
2026-07-30 09:42:41,272 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/basins.geojson.
2026-07-30 09:42:41,275 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/region.geojson.
2026-07-30 09:42:41,275 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/region.geojson.
2026-07-30 09:42:41,278 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_reservoirs_no_control.geojson.
2026-07-30 09:42:41,278 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/meta_reservoirs_no_control.geojson.
2026-07-30 09:42:41,282 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/glaciers.geojson.
2026-07-30 09:42:41,282 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/glaciers.geojson.
2026-07-30 09:42:41,315 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/reservoirs.geojson.
2026-07-30 09:42:41,315 - hydromt.model.components.geoms - geoms - INFO - wflow_sbm.geoms: Writing geoms to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/staticgeoms/reservoirs.geojson.
2026-07-30 09:42:41,319 - hydromt.hydromt_wflow.components.forcing - forcing - INFO - Write forcing file
2026-07-30 09:42:41,319 - hydromt.hydromt_wflow.components.forcing - forcing - INFO - Write forcing file
2026-07-30 09:42:41,328 - hydromt.hydromt_wflow.components.forcing - forcing - INFO - Writing file /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/inmaps.nc
2026-07-30 09:42:41,328 - hydromt.hydromt_wflow.components.forcing - forcing - INFO - Writing file /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/inmaps.nc
[########################################] | 100% Completed | 101.34 ms
2026-07-30 09:42:41,448 - hydromt.model.components.tables - tables - INFO - wflow_sbm.tables: No tables found, skip writing.
2026-07-30 09:42:41,448 - hydromt.model.components.tables - tables - INFO - wflow_sbm.tables: No tables found, skip writing.
2026-07-30 09:42:41,450 - hydromt.model.components.grid - grid - INFO - wflow_sbm.states: Writing grid data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/instate/instates.nc.
2026-07-30 09:42:41,450 - hydromt.model.components.grid - grid - INFO - wflow_sbm.states: Writing grid data to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/instate/instates.nc.
2026-07-30 09:42:41,473 - hydromt.hydromt_wflow.components.config - config - INFO - Writing model config to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/wflow_sbm.toml.
2026-07-30 09:42:41,473 - hydromt.hydromt_wflow.components.config - config - INFO - Writing model config to /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/wflow_sbm.toml.
The example above means the following: run hydromt with:
update wflow: i.e. update a wflow modelwflow_piave_subbasin: original model folder-o ./wflow_piave_corine: output updated model folder-i wflow_update_landuse.yml: setup configuration file containing the components to update and their different options-d artifact_data: specify to use the artifact_data catalog-v: give some extra verbosity (1 * v) to display feedback on screen. Now INFO messages are provided.
Model comparison#
From the information above, you can see that not only was the landuse map updated but also all wflow landuse-related parameters with it: Kext, N, PathFrac, RootingDepth, Sl, Swood and WaterFrac.
Let’s now have a look at the different landuse maps of our two models and check that they were indeed updated.
[7]:
# Load both models with hydromt
model = WflowSbmModel(root="wflow_piave_corine", mode="r")
2026-07-30 09:42:41,483 - hydromt.model.model - model - INFO - Initializing wflow_sbm model from hydromt_wflow (v1.0.3.dev0).
2026-07-30 09:42:41,483 - hydromt.model.model - model - INFO - Initializing wflow_sbm model from hydromt_wflow (v1.0.3.dev0).
2026-07-30 09:42:41,484 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/parameters_data.yml
2026-07-30 09:42:41,484 - hydromt.data_catalog.data_catalog - data_catalog - INFO - Parsing data catalog from /home/runner/work/hydromt_wflow/hydromt_wflow/hydromt_wflow/data/parameters_data.yml
2026-07-30 09:42:41,501 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/wflow_sbm.toml.
2026-07-30 09:42:41,501 - hydromt.hydromt_wflow.components.config - config - INFO - Reading model config file from /home/runner/work/hydromt_wflow/hydromt_wflow/docs/_examples/wflow_piave_corine/wflow_sbm.toml.
2026-07-30 09:42:41,503 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Supported Wflow.jl version v1.1.
2026-07-30 09:42:41,503 - hydromt.hydromt_wflow.wflow_base - wflow_base - INFO - Supported Wflow.jl version v1.1.
[8]:
df = pd.read_csv("./legends/GLOBCOVER_2009_QGIS.txt", header=None, index_col=0)
# plot globcover map
levels = df.index
colors = (df.iloc[:-1, :4] / 255).values
ticklabs = df.iloc[:-1, 4].values
cmap, norm = mpl.colors.from_levels_and_colors(levels, colors)
ticks = np.array(levels[:-1]) + np.diff(levels) / 2.0
# create new figure
fig = plt.figure(figsize=(14, 7))
ax = fig.add_subplot(projection=proj)
# plot globcover landuse
mask = model.staticmaps.data["subcatchment"] > 0
p = (
model.staticmaps.data["meta_landuse"]
.raster.mask_nodata()
.plot(ax=ax, cmap=cmap, norm=norm, cbar_kwargs=dict(ticks=ticks))
)
p.axes.set_title("GlobCover LULC")
_ = p.colorbar.ax.set_yticklabels(ticklabs)
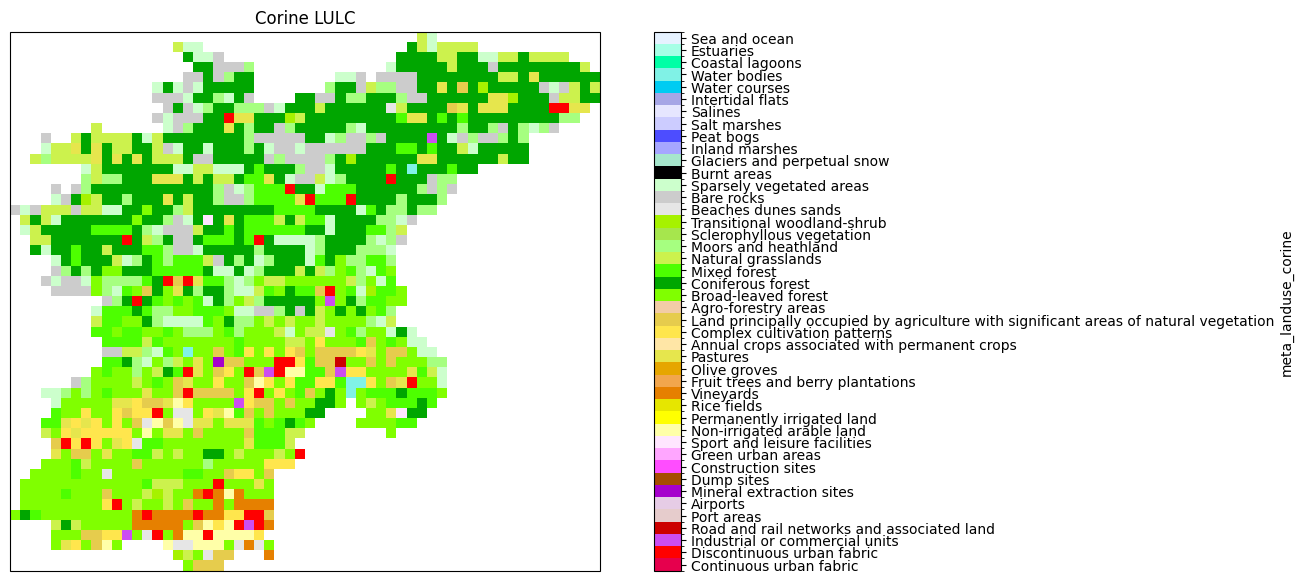
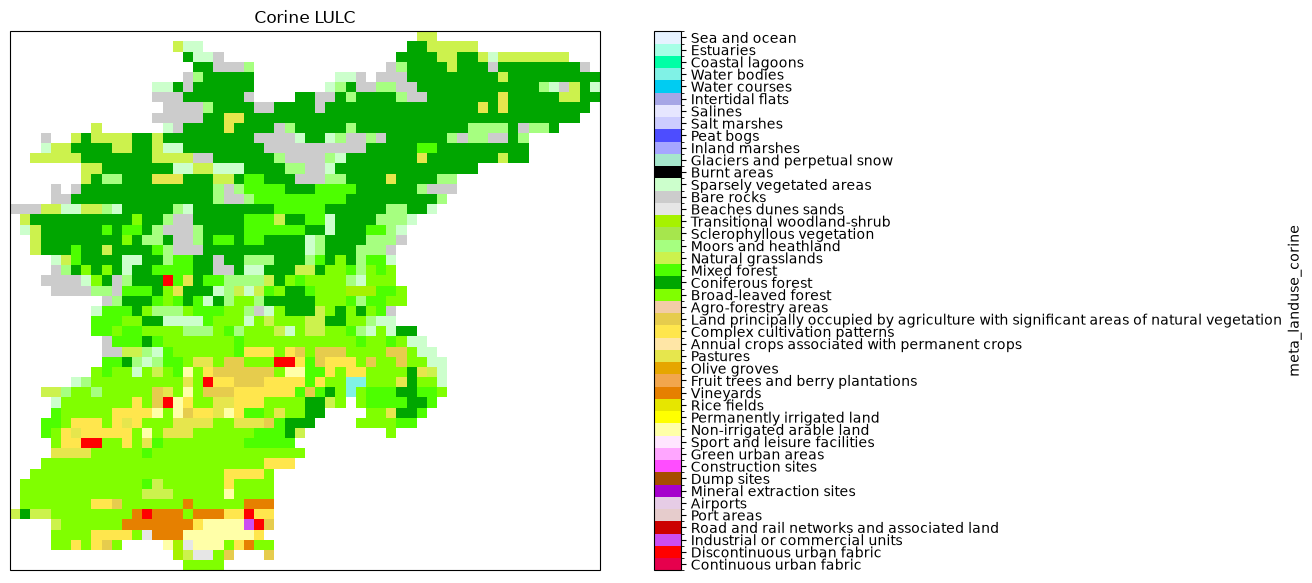
[9]:
# plot corine map
df = pd.read_csv(
"./legends/CLC2018_CLC2018_V2018_20_QGIS.txt", header=None, index_col=0
)
# plot corine map
levels = df.index
colors = (df.iloc[:-1, :4] / 255).values
ticklabs = df.iloc[:-1, 4].values
cmap, norm = mpl.colors.from_levels_and_colors(levels, colors)
ticks = np.array(levels[:-1]) + np.diff(levels) / 2.0
# create new figure
fig = plt.figure(figsize=(14, 7))
ax = fig.add_subplot(projection=proj)
# plot corine landuse
p = (
model.staticmaps.data["meta_landuse_corine"]
.raster.mask_nodata()
.plot(ax=ax, cmap=cmap, norm=norm, cbar_kwargs=dict(ticks=ticks))
)
p.axes.set_title("Corine LULC")
_ = p.colorbar.ax.set_yticklabels(ticklabs)