Tip
Example: Exporting data from a data catalog#
This example illustrates the how to read and export data for a specific region / dates using the HydroMT DataCatalog and the export_data method.
[1]:
# import hydromt and setup logging
import os
import hydromt
from hydromt.log import setuplog
logger = setuplog("export data", log_level=10)
2024-02-26 15:11:42,019 - export data - log - INFO - HydroMT version: 0.9.4
Explore the current data catalog#
For this exercise, we will use the pre-defined catalog artifact_data which contains a global data extracts for the Piave basin in Northern Italy. This data catalog and the actual data linked to it are for a small geographic extent as it is intended for documentation and testing purposes only. If you have another data catalog available (and the linked data), you can use it instead.
To read your own data catalog (as well as a predefined catalog), you can use the data_libs argument of the DataCatalog which accepts either a absolute/relative path to a data catalog yaml file or a name of a pre-defined catalog. First let’s read the pre-defined artifact data catalog:
[2]:
# Download and read artifacts for the Piave basin to `~/.hydromt_data/`.
data_catalog = hydromt.DataCatalog(
logger=logger,
data_libs=["artifact_data"],
)
2024-02-26 15:11:42,203 - export data - data_catalog - INFO - Reading data catalog archive artifact_data v0.0.8
2024-02-26 15:11:42,204 - export data - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt_data/artifact_data/v0.0.8/data_catalog.yml
The artifact_data catalog is one of the pre-defined available DataCatalog of HydroMT. You can find an overview of pre-defined data catalogs in the online user guide. You can also get an overview of the pre-defined catalogs with their version number from HydroMT.
[3]:
from pprint import pprint
pprint(data_catalog.predefined_catalogs)
{'artifact_data': {'notes': 'This data archive contains a sample dataset for '
'the Piave basin (North Italy) to be used for '
'tests and docs/demo purposes.',
'urlpath': 'https://github.com/DirkEilander/hydromt-artifacts/releases/download/{version}/data.tar.gz',
'versions': {'v0.0.6': 'v0.0.6',
'v0.0.7': 'v0.0.7',
'v0.0.8': 'v0.0.8'}},
'aws_data': {'notes': 'This data are stored in public Amazon Web Services.',
'urlpath': 'https://raw.githubusercontent.com/Deltares/hydromt/{version}/data/catalogs/aws_data.yml',
'versions': {'v2023.2': '897e5c5272875f1c066f393798b7ae59721c9e9d',
'v2024.1.30': 'main'}},
'deltares_data': {'notes': 'This data is only accessible when connected to '
'the Deltares network.',
'urlpath': 'https://raw.githubusercontent.com/Deltares/hydromt/{version}/data/catalogs/deltares_data.yml',
'versions': {'v2022.5': 'd88cc47bd4ecc83de38c00aa554a7d48ad23ec23',
'v2022.7': 'e082da339f22cb1fc3571eec5a901a21d1c8a7bd',
'v2023.12.19': 'bf25e79dcbda67612a75588cd782d57abe3881de',
'v2023.12.21': '392206b21b26e62e00ae76db7ffc61a3b95e2175',
'v2023.2': '0bf8e2a1e716095dc6df54a5e9114ce88da0701b',
'v2024.1.30': 'main'}},
'gcs_cmip6_data': {'notes': 'This data uses CMIP6 data stored in Google Cloud '
'Service.',
'urlpath': 'https://raw.githubusercontent.com/Deltares/hydromt/{version}/data/catalogs/gcs_cmip6_data.yml',
'versions': {'v2023.2': '0144d5dadfb76a9f2bdb22226b484e83c9751c34',
'v2024.1.30': 'main'}}}
Let’s now check which data sources are available in the catalog:
[4]:
# For a list of sources including attributes
data_catalog.sources.keys()
[4]:
dict_keys(['chelsa', 'chirps_global', 'corine', 'dtu10mdt', 'dtu10mdt_egm96', 'eobs', 'eobs_orography', 'era5', 'era5_hourly', 'era5_daily_zarr', 'era5_hourly_zarr', 'era5_orography', 'gadm_level1', 'gadm_level2', 'gadm_level3', 'gcn250', 'gdp_world', 'gebco', 'ghs-smod_2015_v2', 'ghs_pop_2015', 'ghs_pop_2015_54009', 'ghs_smod_2015', 'globcover', 'glw_buffaloes', 'glw_cattle', 'glw_chicken', 'glw_ducks', 'glw_goats', 'glw_horses', 'glw_pigs', 'glw_sheep', 'grdc', 'grip_roads', 'grwl', 'grwl_mask', 'gswo', 'gtsmv3_eu_era5', 'guf_bld_2012', 'hydro_lakes', 'hydro_reservoirs', 'koppen_geiger', 'mdt_cnes_cls18', 'merit_hydro', 'merit_hydro_1k', 'merit_hydro_index', 'modis_lai', 'osm_coastlines', 'osm_landareas', 'rgi', 'rivers_lin2019_v1', 'simard', 'soilgrids', 'vito', 'wb_countries', 'worldclim'])
And let’s now open a plot one of the available datasets to check extent and available dates:
[5]:
ds = data_catalog.get_rasterdataset("era5", time_tuple=("2010-02-02", "2010-02-15"))
print("")
print(f"Available extent: {ds.raster.bounds}")
print(f"Available dates: {ds.time.values[0]} to {ds.time.values[-1]}")
ds
2024-02-26 15:11:42,267 - export data - rasterdataset - INFO - Reading era5 netcdf data from /home/runner/.hydromt_data/artifact_data/v0.0.8/era5.nc
2024-02-26 15:11:42,321 - export data - rasterdataset - DEBUG - Shifting time labels with 86400 sec.
2024-02-26 15:11:42,323 - export data - rasterdataset - DEBUG - Slicing time dim ('2010-02-02', '2010-02-15')
2024-02-26 15:11:42,326 - export data - rasterdataset - DEBUG - Convert units for 7 variables.
Available extent: (11.625, 45.125, 13.125, 46.875)
Available dates: 2010-02-02T00:00:00.000000000 to 2010-02-15T00:00:00.000000000
[5]:
<xarray.Dataset> Size: 17kB
Dimensions: (time: 14, latitude: 7, longitude: 6)
Coordinates:
* time (time) datetime64[ns] 112B 2010-02-02 2010-02-03 ... 2010-02-15
* longitude (longitude) float32 24B 11.75 12.0 12.25 12.5 12.75 13.0
* latitude (latitude) float32 28B 46.75 46.5 46.25 46.0 45.75 45.5 45.25
spatial_ref int32 4B ...
Data variables:
precip (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
temp (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
press_msl (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
kin (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
kout (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
temp_min (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
temp_max (time, latitude, longitude) float32 2kB dask.array<chunksize=(14, 7, 6), meta=np.ndarray>
Attributes:
category: meteo
history: Extracted from Copernicus Climate Data Store; resampled ...
paper_doi: 10.1002/qj.3803
paper_ref: Hersbach et al. (2019)
source_license: https://cds.climate.copernicus.eu/cdsapp/#!/terms/licenc...
source_url: https://doi.org/10.24381/cds.bd0915c6
source_version: ERA5 daily data on pressure levelsExport an extract of the data#
Now we will export a subset of the data in our artifact_data catalog using the DataCatalog.export_data method. Let’s check the method’s docstring:
[6]:
?data_catalog.export_data
Let’s select which data source and the extent we want (based on the exploration above):
[7]:
# List of data sources to export
# NOTE that for ERA5 we only export the precip variable and for merit_hydro we only export the elevtn variable
source_list = ["merit_hydro[elevtn,flwdir]", "era5[precip]", "vito"]
# Geographic extent
bbox = [12.0, 46.0, 13.0, 46.5]
# Time extent
time_tuple = ("2010-02-10", "2010-02-15")
And let’s export the tmp_data_export folder:
[8]:
folder_name = "tmp_data_export"
data_catalog.export_data(
data_root=folder_name,
bbox=bbox,
time_tuple=time_tuple,
source_names=source_list,
meta={"version": "1"},
)
2024-02-26 15:11:42,438 - export data - data_catalog - DEBUG - Exporting merit_hydro.
2024-02-26 15:11:42,441 - export data - rasterdataset - INFO - Reading merit_hydro raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro/{variable}.tif
2024-02-26 15:11:42,476 - export data - rasterdataset - DEBUG - Clip to [12.000, 46.000, 13.000, 46.500] (epsg:4326))
2024-02-26 15:11:42,659 - export data - data_catalog - DEBUG - Exporting era5.
2024-02-26 15:11:42,660 - export data - rasterdataset - INFO - Reading era5 netcdf data from /home/runner/.hydromt_data/artifact_data/v0.0.8/era5.nc
2024-02-26 15:11:42,675 - export data - rasterdataset - DEBUG - Shifting time labels with 86400 sec.
2024-02-26 15:11:42,677 - export data - rasterdataset - DEBUG - Slicing time dim ('2010-02-10', '2010-02-15')
2024-02-26 15:11:42,687 - export data - rasterdataset - DEBUG - Clip to [12.000, 46.000, 13.000, 46.500] (epsg:4326))
2024-02-26 15:11:42,689 - export data - rasterdataset - DEBUG - Convert units for 1 variables.
2024-02-26 15:11:42,704 - export data - data_catalog - DEBUG - Exporting vito.
2024-02-26 15:11:42,705 - export data - rasterdataset - INFO - Reading vito raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/vito.tif
2024-02-26 15:11:42,721 - export data - rasterdataset - DEBUG - Clip to [12.000, 46.000, 13.000, 46.500] (epsg:4326))
Open and explore the exported data#
Now we have our new extracted data and HydroMT saved as well a new data catalog file that goes with it:
[9]:
import os
for path, _, files in os.walk(folder_name):
print(path)
for name in files:
print(f" - {name}")
tmp_data_export
- data_catalog.yml
- vito.tif
tmp_data_export/merit_hydro
- flwdir.tif
- elevtn.tif
tmp_data_export/era5
- precip.nc
[10]:
with open(os.path.join(folder_name, "data_catalog.yml"), "r") as f:
print(f.read())
meta:
version: '1'
root: /home/runner/work/hydromt/hydromt/docs/_examples/tmp_data_export
era5:
data_type: RasterDataset
path: era5/{variable}.nc
driver: netcdf
filesystem: local
meta:
category: meteo
history: Extracted from Copernicus Climate Data Store; resampled by Deltares to
daily frequency
paper_doi: 10.1002/qj.3803
paper_ref: Hersbach et al. (2019)
source_license: https://cds.climate.copernicus.eu/cdsapp/#!/terms/licence-to-use-copernicus-products
source_url: https://doi.org/10.24381/cds.bd0915c6
source_version: ERA5 daily data on pressure levels
crs: 4326
merit_hydro:
data_type: RasterDataset
path: merit_hydro/{variable}.tif
driver: raster
filesystem: local
meta:
category: topography
paper_doi: 10.1029/2019WR024873
paper_ref: Yamazaki et al. (2019)
source_license: CC-BY-NC 4.0 or ODbL 1.0
source_url: http://hydro.iis.u-tokyo.ac.jp/~yamadai/MERIT_Hydro
source_version: 1.0
crs: 4326
vito:
data_type: RasterDataset
path: vito.tif
driver: raster
filesystem: local
meta:
category: landuse & landcover
paper_doi: 10.5281/zenodo.3939038
paper_ref: Buchhorn et al (2020)
source_url: https://land.copernicus.eu/global/products/lc
source_version: v2.0.2
crs: 4326
Let’s open the extracted data catalog:
[11]:
data_catalog_extract = hydromt.DataCatalog(
data_libs=os.path.join(folder_name, "data_catalog.yml")
)
data_catalog_extract.sources.keys()
[11]:
dict_keys(['era5', 'merit_hydro', 'vito'])
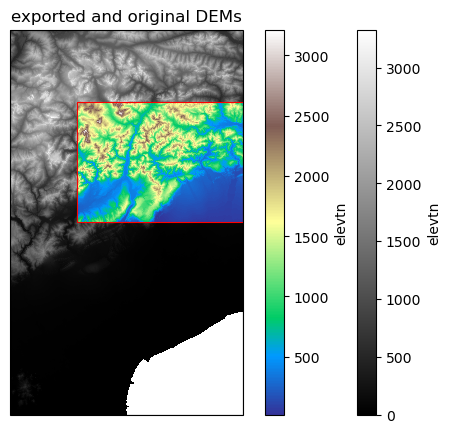
And now let’s open the extracted data again and do a nice plot.
[12]:
# Get both the extracted and original merit_hydro_1k DEM
dem = data_catalog.get_rasterdataset(
"merit_hydro", variables=["elevtn"], bbox=[11.6, 45.2, 13.0, 46.8]
)
dem_extract = data_catalog_extract.get_rasterdataset(
"merit_hydro", variables=["elevtn"]
)
2024-02-26 15:11:42,763 - export data - rasterdataset - INFO - Reading merit_hydro raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro/{variable}.tif
2024-02-26 15:11:42,778 - export data - rasterdataset - DEBUG - Clip to [11.600, 45.200, 13.000, 46.800] (epsg:4326))
[13]:
import matplotlib.pyplot as plt
import geopandas as gpd
from shapely.geometry import box
import cartopy.crs as ccrs
proj = ccrs.PlateCarree() # plot projection
# get bounding box of each data catalog using merit_hydro_1k
bbox = gpd.GeoDataFrame(geometry=[box(*dem.raster.bounds)], crs=4326)
bbox_extract = gpd.GeoDataFrame(geometry=[box(*dem_extract.raster.bounds)], crs=4326)
# Initialise plot
fig = plt.figure(figsize=(7, 5))
ax = fig.add_subplot(projection=proj)
# Plot the bounding box
bbox.boundary.plot(ax=ax, color="k", linewidth=0.8)
bbox_extract.boundary.plot(ax=ax, color="red", linewidth=0.8)
# Plot elevation
dem.raster.mask_nodata().plot(ax=ax, cmap="gray")
dem_extract.raster.mask_nodata().plot(ax=ax, cmap="terrain")
ax.set_title("exported and original DEMs")
[13]:
Text(0.5, 1.0, 'exported and original DEMs')