User guide#
HydroMT (Hydro Model Tools) is an open-source Python package that facilitates the process of building and analyzing spatial geoscientific models with a focus on water system models. It does so by automating the workflow to go from raw data to a complete model instance which is ready to run and to analyse model results once the simulation has finished. As such it is an interface between user, data and hydro models.
The functionality of HydroMT can be broken down into three components, which are around input data, model instances, and methods and workflows. Users can interact with HydroMT through a high-level command line interface (CLI) to build model instances from scratch, update existing model instances or analyze model results. Furthermore, a Python interface is available that exposes all functionality for experienced users. A schematic overview of the package architecture is provided in the figure below and each HydroMT component is discussed below.
In short, there are three important concepts in HydroMT core that are important to cover:
DataAdaptersandDataCatalog: These are what basically hold all information about how to approach and read data as well as some of the metadata about it. While a lot of the work in HydroMT happens here, plugins or users shouldn’t really need to know about these beyond using the properdata_typein their configuration.DataCatalogare basically just a thin wrapper around theDataAdaptersthat does some book keeping.Workflows: These are functions that transform input data and can call a set of methods to for example, resample, fill nodata, reproject, derive other variables etc. The core has some of these workflows but you may need new ones for your plugin.Model: This is where the magic happens (as far as the plugin is concerned). We have provided some generic models that you can override to get basic/generic functionality, but using the model functionality is where it will be at for you. The scheme below lists the current relationship between the HydroMTModeland generic sub-Model classes and the know plugins.
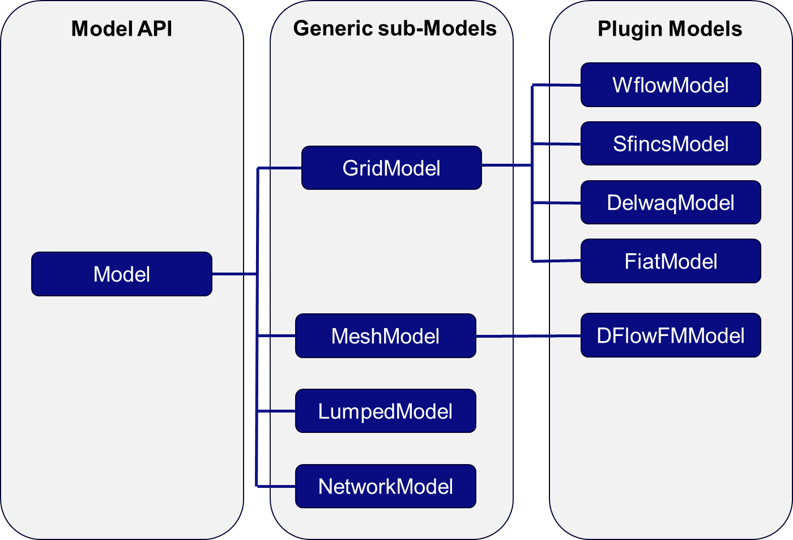
Schematic of Model and plugin structure of HydroMT#
More concretely HydroMT is organized in the following way:
Input Data
HydroMT is data-agnostic through the Data Adapter, which reads a wide range of data formats and unifies the input data (e.g., on-the-fly renaming and unit conversion). Datasets are listed and passed to HydroMT in a user defined data catalog yaml file.. HydroMT also provides several pre-defined data catalogs with mostly global datasets that can be used as is, although not all datasets in these catalogs are openly accessible. Currently, four different types of input data are supported and represented by a specific Python data object: gridded datasets such as DEMs or gridded spatially distributed rainfall datasets (represented by RasterDataset objects, a raster-specific type of Xarray Datasets); tables that can be used to, for example, convert land classes to roughness values (represented by Pandas DataFrame objects); vector datasets such as administrative units or river center lines (represented by Geopandas GeoDataFrame objects); and time series with associated geo-locations such as observations of discharge (represented by GeoDataset objects, a geo-specific type of Xarray Datasets).
Models
HydroMT defines any model instance through the model-agnostic Model API based on several components: maps, geometries, forcings, results, states, and the model simulation configuration. For different types of general model classes (i.e., gridded, vector, mesh and network models) additional model components have been defined. Each component is represented with a specific Python data object to provide a common interface to different model software. Model instances can be built from scratch, and existing models can be updated based on a pipeline of methods defined in a model configuration .yaml file. While HydroMT provides several general model classes that can readily be used, it can also be tailored to specific model software through a plugin infrastructure. These plugins have the same interface, but with model-specific file readers, writers and workflows.
Methods and workflow
Most of the heavy work in HydroMT is done by Methods and workflows, indicated by the gear wheels in the image Schematic of HydroMT architecture below. Methods provide the low-level functionality such as GIS rasterization, reprojection, or zonal statistics. Workflows combine several methods to transform data to a model layer or post-process model results. Examples of workflows include the delineation of hydrological basins (watersheds), conversion of landuse-landcover data to model parameter maps, and calculation of model skill statistics. Workflows are implemented for the data types mentioned above to allow reusing common workflows between HydroMT plugins for different model software.
A user can interact with HydroMT through the following interfaces:
Command Line Interface (CLI)
The CLI is a high-level interface to HydroMT. It is used to run HydroMT methods such as build, update or clip.
Python Interface
While most common functionalities can be called through the CLI, the Python interface offers more flexibility for advanced users. It allows you to e.g. interact directly with a model component Model API and apply the many methods and workflows available. Please find all available functions API reference
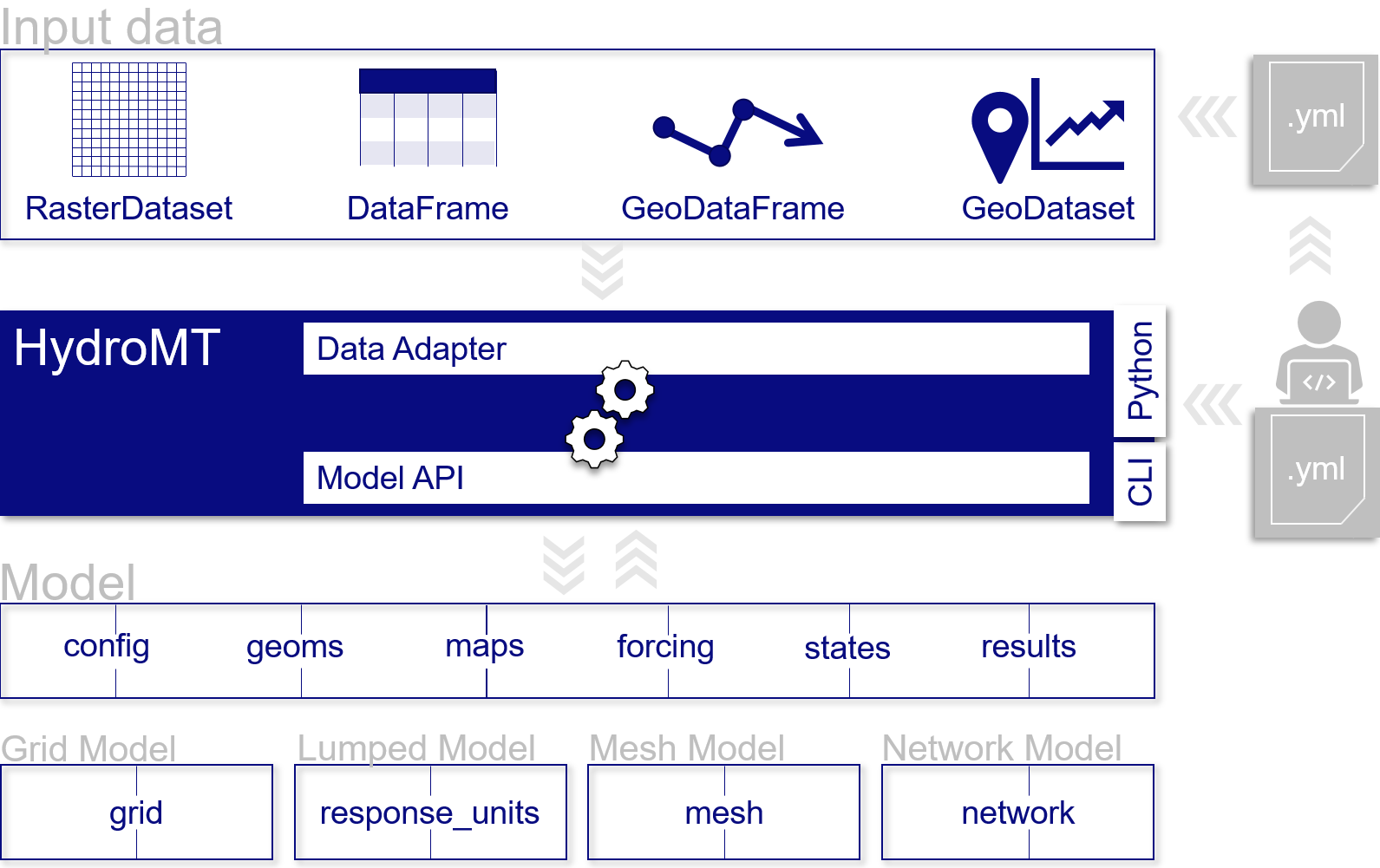
Schematic of HydroMT architecture#
Terminology#
HydroMT and this documentation use a specific terminology to describe specific objects or processes.
Term |
Explanation |
|---|---|
Command Line Interface (CLI) |
high-level interface to HydroMT build, update and clip methods. |
Configuration (HydroMT) |
(.yaml) file describing the complete pipeline with all methods and their arguments to build or update a model. |
Data catalog |
A set of data sources available for HydroMT. It is build up from yaml files containing one or more data sources with information about how to read and optionally preprocess the data and contains meta-data about the data source. |
Data source |
Input data to be processed by HydroMT. Data sources are listed in yaml files. |
Model |
A set of files describing the schematization, forcing, states, simulation configuration and results for any supported model kernel and model classes. The final set of files is dependent on the model type (grid, vector or mesh model for examples) or the model plugin. |
Model class |
A model instance can be instantiated from different model schematization concepts. Generalized model classes currently supported within HydroMT are Grid Model (distributed models), vector Model (semi-distributed), Mesh Model (unstructured) and in the future Network Model (relational model). Specific model classes for specific softwares have been implemented as plugins, see Model plugin. |
Model attributes |
Direct properties of a model, such as the model root. They can be called when using HydroMT from python. |
Model component |
A model is described by HydroMT with the following components: maps, geoms (vector data), forcing, results, states, config, grid (for a grid model), vector (for a vector model), mesh (for a mesh model). |
Model plugin |
Model software for which HydroMT can build and update models and analyze its simulation results. For example Wflow, SFINCS etc. |
Model kernel |
The model software to execute a model simulation. This is not part of any HydroMT plugin. |
Region |
Argument of the build and clip CLI methods that specifies the region of interest where the model should be prepared / which spatial subregion should be clipped. |