Custom Models#
The main goal of your plugin is to be able to build and update model instances for your own software. As a reminder, the figure below illustrates the process of model building in HydroMT:
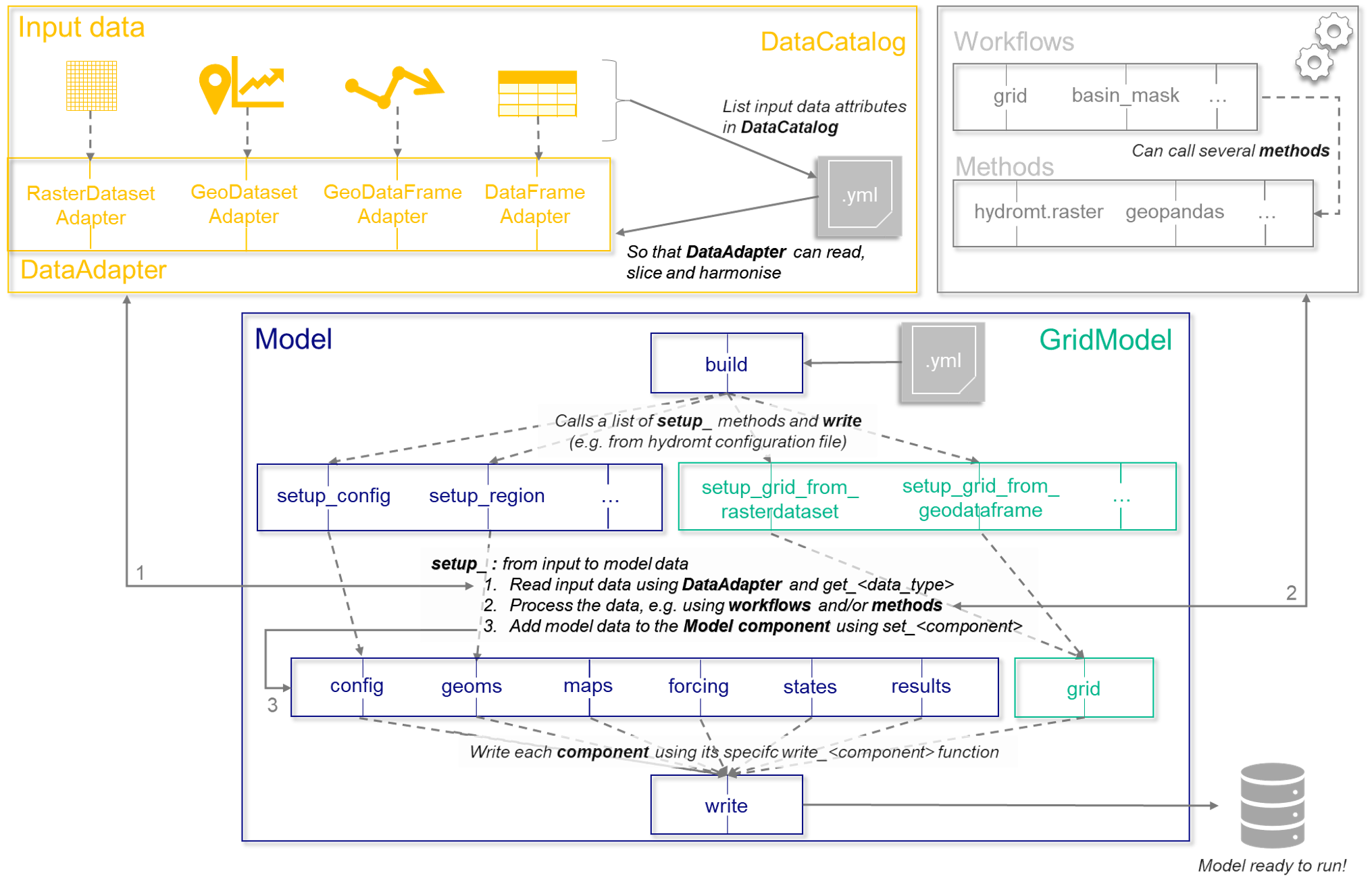
Model building process in HydroMT.#
In this section, we will detail the bottom part of the schematic above ie how to initialise your HydroMT Model class for your plugin, the main properties and setup methods and how to work with its model components. The top part of the schematic (data preparation) is taken care of by the core of HydroMT.
Initialisation#
Most of the functionality necessary to initialise models is already taken care of in
Core, therefore if you inherit from the core Model class you should not have to
implement much or even any of the basic functionalities.
If you wish to provide default behaviour for your users, such as providing default
components that your model will always need, you can do so by overriding the __init__
function on your model like so:
class AwesomeModel:
def __init__(self, ...):
super().__init__(...)
self.add_component("extra_grid", GridComponent)
# extra customisation code here...
Please make sure to call the super().__init__ function before you do anything else to
setup your class so that the base functionality also get’s run properly.
Additional Model properties#
You can have a look at the Model API documentation to find out all other properties of the Model class and
the other subclasses. Apart from the components here are a couple of useful properties to use when developing your plugin:
root: path to the root folder of the model instance you are working with.crs: the reference coordinate system (pyproj.CRS) of the model.region: A shortcut to retrieve region data from the designated spacial componentdata_catalog: the current data catalog you can use to add data to your model.logger: the HydroMT logger object for your model instance.
Setup basic model objects#
When building a model from scratch, the first thing you should do is take inventory of what your components need. As already mentioned most of the behaviour will be defined in the components, but overarching functionality that doesn’t necessarily belong to a single component such as for example adding perturbations for a sensitivity analysis can still be defined in the Model class itself.
Any additional functionality that you define on either your model or your model components that is annotated with the @hydromt_step decorator should be available to your users through the workflow yaml interface automatically.
Note
Order of the setup methods: Typically, building a model starts with defining the computational units (grid, mesh, vector etc.). Afterwards data layers are added to model components and there might be dependencies between the different layers. For example, a method to define river dimensions should probably be called after a method which defines the river cells on the grid or mesh itself. However, there is no real check on the order in which setup methods are called apart from checks that you can build-in that certain layers are already present with clear error messages. Clear documentation will help your user too. For Command Line Interface users, the functions in the hydromt configuration yaml file will be executed in the order they appear in the file. Python Interface users can call the setup functions in any order they want from a script.
Setup methods#
In general, a HydroMT setup_<> method does 4 things:
read and parse the data using the
DataCatalogprocess that data in some way, optionally by calling other functions.
Optionally, rename or update attributes from HydroMT variable conventions (name, unit) to the specific model conventions.
add the data to the corresponding HydroMT model components.
Below is a simplified example of what a setup function would look like for a hypothetical landuse grid from a raster input data:
def setup_landuse(
self,
landuse: Union[str, Path, xr.DataArray],
):
"""Add landuse data variable to grid.
Adds model layers:
* **landuse_class** grid: data from landuse
Parameters
----------
landuse: str, Path, xr.DataArray
Data catalog key, path to raster file or raster xarray data object.
If a path to a raster file is provided it will be added
to the data_catalog with its name based on the file basename without
extension.
"""
self.logger.info(f"Preparing landuse data from raster source {landuse}")
# 1. Read landuse raster data
da_landuse = self.data_catalog.get_rasterdataset(
landuse,
geom=self.region,
buffer=2,
variables=["landuse"],
)
# 2. Do some transformation or processing
ds_out = hydromt.model.processes.grid.grid_from_rasterdataset(
grid_like=self.grid,
ds=da_landuse,
fill_method="nearest",
reproject_method="mode",
)
# 3. Rename or transform from HydroMT to model conventions
rmdict = {"landuse": "landuse_class"}
# Or using a properly initialised _GRIDS
# rmdict = {k: v for k, v in self._GRIDS.items() if k in ds_out.data_vars}
ds_out = ds_out.rename(rmdict)
# 4. Add to grid
self.set_grid(ds_out)
Note
Input data type of the setup method: Typically a setup function tries to go from one type of dataset
(landuse raster) to a HydroMT model component (landuse map in maps). So it’s good to make clear for your user in
the setup function docstrings which type of input data this function can work with. You could decide to support
several data types in one setup function but be aware that the GIS processing functions like resampling, reprojection can
be quite different for a raster or a vector for example. So you could decide to create two setup functions that
prepare the same data but from different type of input data (eg setup_landuse_from_raster and setup_landuse_from_vector).
Processes#
We encourage developers and users to define their functionality using functions that can be organised into separate modules or scripts. This can keep your class definitions from becoming very large unwieldy to work with as well as making it easier to make sure all the functionalities are properly tested (which we encourage even more strongly!). In HydroMT these functionalities are usually called processes (prior to V1 these were called workflows, but that name is now used for the yaml interface, and therefore were renamed to processes). These processes are usually stored in separate python scripts that you can decide to store in a process subfolder.
A couple of tips if you want to define processes:
check out the process available in HydroMT core
avoid passing the HydroMT model class to your process function, but pass the required arguments directly. try to do this:
def interpolate_grid(grid: xr.DataSet, crs: CRS): ...
not this:
def interpolate_grid(model: AwesomeModel): grid = model.grid ...
Ideally the workflows work from common python objects like xarray or geopandas rather than with the
Modelclass.if you want to do some GIS processing on
RasterDatasetorGeoDataset, HydroMT defines a lot of useful methods. Check out the :ref: Raster methods API doc for RasterDataset and :ref: GeoDataset methods API doc. ForGeoDataFrame, the geopandas library should have most of what you need (and forUgridDatasetor mesh, the xugrid library). For computing or deriving other variables from an input dataset, HydroMT contains also a couple of useful workflows for exampleflwdirfor flow direction methods,basin_maskto derive basin shape, orstatsto derive general, efficiency or extreme value statistics from data.