Tip
Prepare flow directions and related data from a DEM#
With HydroMT-Wflow, a user can choose to build a model in a geographic or projected coordinate system from an input Digital Elevation Model (DEM) and Flow Direction (flwdir) dataset.
While DEM data are often available, this is not the always the case for the flow directions (flwdir). We made the choice to build a Wflow model directly from user provided DEM and flwdir datasets rather than reprojecting a DEM and/or deriving flwdir on the fly. This is because deriving flow directions is often an iterative process to be sure the flow directions matche the terrain and river network. Note that for the best results the flwdir data should be derived from a high-res DEM (<100 m spatial resolution). The HydroMT-Wflow model builder will automatically resample the flwdir data to the model resolution.
Because of this, we prefer to provide this notebook as a possible pre-processing step before calling a build a Wflow model with HydroMt-Wflow. Here we use the different flow directions methods from HydroMT and PyFlwDir
Load dependencies#
[1]:
import os
import xarray as xr
import numpy as np
import geopandas as gpd
# pyflwdir
import pyflwdir
# hydromt
from hydromt import DataCatalog, flw
# plot
import matplotlib.pyplot as plt
from matplotlib import cm, colors
import cartopy.crs as ccrs
[2]:
# we assume the model maps are in the geographic CRS EPSG:4326
proj = ccrs.PlateCarree()
# create nice elevation colormap
c_dem = plt.cm.terrain(np.linspace(0.25, 1, 256))
cmap = colors.LinearSegmentedColormap.from_list("dem", c_dem)
norm = colors.Normalize(vmin=0, vmax=2000)
kwargs = dict(cmap=cmap, norm=norm)
# legend settings
legend_kwargs = dict(
title="Legend",
loc="lower right",
frameon=True,
framealpha=0.7,
edgecolor="k",
facecolor="white",
)
def add_legend_titles(ax, title, add_legend=True, projected=True):
ax.xaxis.set_visible(True)
ax.yaxis.set_visible(True)
if projected:
ax.set_xlabel("Easting [m]")
ax.set_ylabel("Northing [m]")
else:
ax.set_ylabel("latitude [degree north]")
ax.set_xlabel("longitude [degree east]")
_ = ax.set_title(title)
if add_legend:
legend = ax.legend(**legend_kwargs)
return legend
Deriving flow directions from Elevation data#
In this example we will use the merit_hydro data in the pre-defined artifact_data catalog of HydroMT. Note that this dataset already provides flow direction, but for sake of example we only use this as reference dataset.
First let’s read the data:
[3]:
data_catalog = DataCatalog("artifact_data")
merit = data_catalog.get_rasterdataset(
"merit_hydro", variables=["elevtn", "flwdir"], bbox=[12, 46.0, 12.3, 46.2]
)
Dataset does [12.000000000000016, 45.99999999999999, 12.300000000000011, 46.199999999999996] does not fully cover bbox [12.000, 46.000, 12.300, 46.200]
To derive flow directions from a DEM, you can use the hydromt.flw.d8_from_dem method of HydroMT.
This method derives D8 flow directions grid from an elevation grid and allows several options to the users: - outlets: outlets can be defined at edges of the grid (defualt) or force all flow to go to the minimum elevation point min. The latter only makes sense if your DEM only is masked to the catchment. Additionnally, the user can also force specific pits locations via idxs_pit. - depression filling: local depressions are filled based on their lowest pour point level if
the pour point depth is smaller than the maximum pour point depth max_depth, otherwise the lowest elevation in the depression becomes a pit. By default max_depth is set to -1 m filling all local depressions. - river burning: while it is already possible to provide a river vector layer gdf_stream with uparea (km2) column to further guide the derivation of flow directions, this option is currently being improved and not yet fully functional. See also HydroMT core PR
305
Let’s see an example:
[4]:
# Derive flow directions with outlets at the edges -> this is the default
merit["flwdir_derived"] = flw.d8_from_dem(
da_elv=merit["elevtn"],
gdf_stream=None,
max_depth=-1, # no local pits
outlets="edge",
idxs_pit=None,
)
# Get the CRS and check if it is projected or not
is_geographic = merit.raster.crs.is_geographic
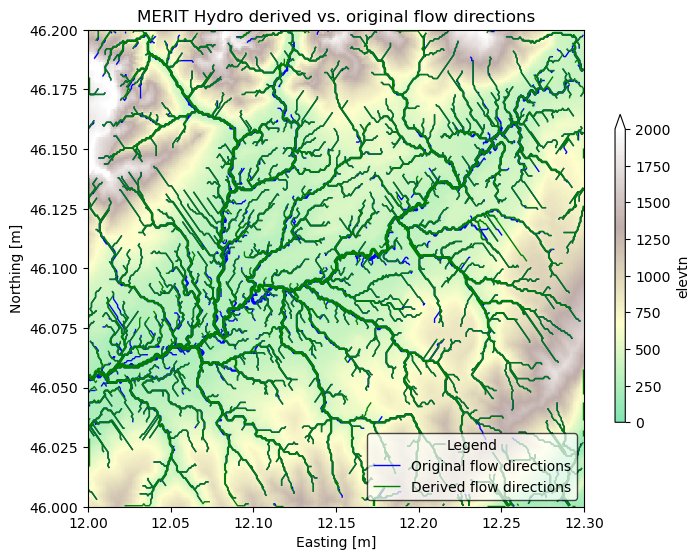
Let’s compare the orignal with the derived flow direction data
[5]:
# plot
# initialize image with geoaxes
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot()
## plot elevation\
merit["elevtn"].plot(
ax=ax, zorder=1, cbar_kwargs=dict(aspect=30, shrink=0.5), alpha=0.5, **kwargs
)
# plot flwdir
flwdir = flw.flwdir_from_da(merit["flwdir"], ftype="infer", check_ftype=True)
feat = flwdir.streams(min_sto=3) # minimum stream order for plotting
gdf = gpd.GeoDataFrame.from_features(feat, crs=merit.raster.crs)
gdf.to_crs(merit.raster.crs).plot(
ax=ax, color="blue", linewidth=gdf["strord"] / 3, label="Original flow directions"
)
# plot flwdir edge
flwdir_edge = flw.flwdir_from_da(
merit["flwdir_derived"], ftype="infer", check_ftype=True
)
feate = flwdir_edge.streams(min_sto=3) # minimum stream order for plotting
gdfe = gpd.GeoDataFrame.from_features(feate, crs=merit.raster.crs)
gdfe.plot(
ax=ax,
column="strord",
color="green",
linewidth=gdfe["strord"] / 3,
label="Derived flow directions",
)
legend = add_legend_titles(ax, "MERIT Hydro derived vs. original flow directions")
Deriving other DEM and flow directions related data#
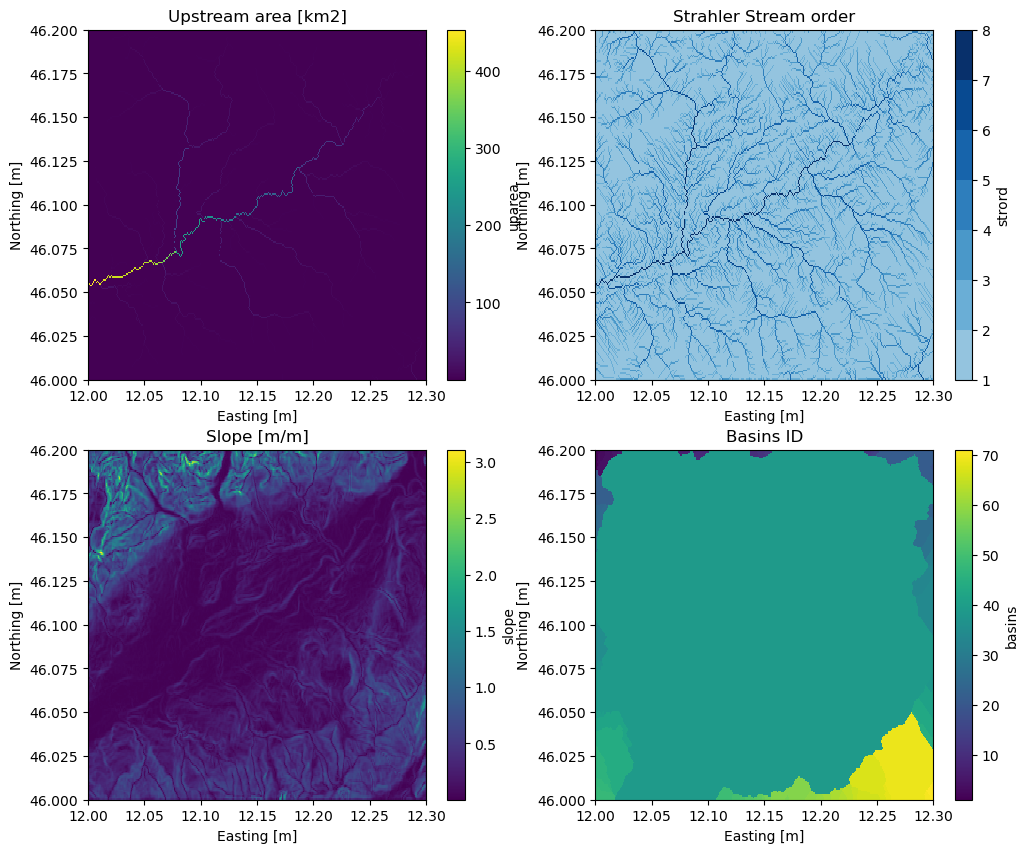
Once you are satisfied with your flow direction map, you can create additionnal derived variables like upstream area or streamorder that can prove useful for example to build a model based on subbasin region.
Here are some examples how to do that using PyFlwdir methods.
[6]:
# Create a new merit_adapted dataset with the riverburn flow directions
merit_adapted = merit["elevtn"].to_dataset(name="elevtn")
merit_adapted["flwdir"] = merit["flwdir_derived"]
dims = merit_adapted.raster.dims
# Create a PyFlwDir object from the dataset
flwdir = flw.flwdir_from_da(merit_adapted["flwdir"])
# uparea
uparea = flwdir.upstream_area(unit="km2")
merit_adapted["uparea"] = xr.Variable(dims, uparea, attrs=dict(_FillValue=-9999))
# stream order
strord = flwdir.stream_order()
merit_adapted["strord"] = xr.Variable(dims, strord)
merit_adapted["strord"].raster.set_nodata(255)
# slope
slope = pyflwdir.dem.slope(
elevtn=merit_adapted["elevtn"].values,
nodata=merit_adapted["elevtn"].raster.nodata,
latlon=is_geographic, # True if geographic crs, False if projected crs
transform=merit_adapted["elevtn"].raster.transform,
)
merit_adapted["slope"] = xr.Variable(dims, slope)
merit_adapted["slope"].raster.set_nodata(merit_adapted["elevtn"].raster.nodata)
# basin at the pits locations
basins = flwdir.basins(idxs=flwdir.idxs_pit).astype(np.int32)
merit_adapted["basins"] = xr.Variable(dims, basins, attrs=dict(_FillValue=0))
# basin index file
gdf_basins = merit_adapted["basins"].raster.vectorize()
merit_adapted
[6]:
<xarray.Dataset>
Dimensions: (x: 360, y: 240)
Coordinates:
* x (x) float64 12.0 12.0 12.0 12.0 12.0 ... 12.3 12.3 12.3 12.3
* y (y) float64 46.2 46.2 46.2 46.2 46.2 ... 46.0 46.0 46.0 46.0
spatial_ref int64 0
Data variables:
elevtn (y, x) float32 dask.array<chunksize=(240, 360), meta=np.ndarray>
flwdir (y, x) uint8 0 16 1 0 16 1 1 0 16 ... 0 16 16 16 16 1 0 16 16
uparea (y, x) float64 0.2199 0.005943 0.005943 ... 0.2326 0.005965
strord (y, x) uint8 2 1 1 2 1 1 2 3 2 1 1 2 ... 6 1 3 3 3 2 1 1 3 2 1
slope (y, x) float32 0.5143 0.5413 0.2722 ... 0.1841 0.1583 0.1146
basins (y, x) int32 1 1 2 2 2 3 3 3 3 3 ... 70 70 70 70 70 71 71 71 71[7]:
# plot
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# plot uparea
merit_adapted["uparea"].plot(ax=axes[0, 0])
_ = add_legend_titles(axes[0, 0], "Upstream area [km2]", add_legend=False)
# plot strord
merit_adapted["strord"].plot(
ax=axes[0, 1], cmap=colors.ListedColormap(cm.Blues(np.linspace(0.4, 1, 7)))
)
_ = add_legend_titles(axes[0, 1], "Strahler Stream order", add_legend=False)
# plot slope
merit_adapted["slope"].plot(ax=axes[1, 0])
_ = add_legend_titles(axes[1, 0], "Slope [m/m]", add_legend=False)
# plot basins
merit_adapted["basins"].plot(ax=axes[1, 1])
_ = add_legend_titles(axes[1, 1], "Basins ID", add_legend=False)
Exporting the newly created data and corresponding data catalog#
Finally, once we are happy with the new dataset, we can write out the data and create the corresponding data catalog so that it can be re-used to build a new wflow model.
[8]:
# Export the gridded data as tif files in a new folder
output_path = "./elevation_data"
# export the hydrography data as tif files (one per variable)
merit_adapted.raster.to_mapstack(
root=os.path.join(output_path, "merit_adapted"),
driver="GTiff",
)
# export the basin index as geosjon
gdf_basins.to_file(
os.path.join(output_path, "merit_adapted_basins.geojson"), driver="GeoJSON"
)
Now let’s prepare the corresponding data catalog: (the writefile command will directly write a file using the lines in the jupyter cell)
[9]:
%%writefile ./elevation_data/data_catalog.yml
merit_adapted:
data_type: RasterDataset
driver: raster
crs: 3857
path: ./merit_adapted/{variable}.tif
rename:
slope: lndslp
meta:
category: topography
paper_doi: 10.5194/hess-2020-582
paper_ref: Eilander et al. (2021)
source_license: ODC-By 1.0
source_url: https://zenodo.org/record/5166932#.YVbxJ5pByUk
source_doi: 10.5281/zenodo.5166932
source_version: 1.0
processing_notes: prepared from MERIT Hydro IHU by deriving flow directions with river burning from lin2019_v1 rivers using pyflwdir.
processing_script: prepare_ldd.ipynb from hydromt_wflow repository
merit_adapted_index:
data_type: GeoDataFrame
driver: vector
crs: 3857
path: ./merit_adapted_basins.geojson
meta:
category: topography
paper_doi: 10.5194/hess-2020-582
paper_ref: Eilander et al. (2021)
source_license: ODC-By 1.0
source_url: https://zenodo.org/record/5166932#.YVbxJ5pByUk
source_doi: 10.5281/zenodo.5166932
source_version: 1.0
processing_notes: prepared from MERIT Hydro IHU by deriving flow directions with river burning from lin2019_v1 rivers using pyflwdir.
processing_script: prepare_ldd.ipynb from hydromt_wflow repository
Writing ./elevation_data/data_catalog.yml
And now let’s try to load our data again with hydromt:
[10]:
data_catalog = DataCatalog(data_libs="./elevation_data/data_catalog.yml")
merit_utm = data_catalog.get_rasterdataset("merit_adapted")
merit_utm
RasterDataset merit_adapted: CRS from data catalog does not match CRS of data. The original CRS will be used. Please check your catalog.
[10]:
<xarray.Dataset>
Dimensions: (x: 360, y: 240)
Coordinates:
* x (x) float64 12.0 12.0 12.0 12.0 12.0 ... 12.3 12.3 12.3 12.3
* y (y) float64 46.2 46.2 46.2 46.2 46.2 ... 46.0 46.0 46.0 46.0
spatial_ref int64 0
Data variables:
basins (y, x) int32 dask.array<chunksize=(240, 360), meta=np.ndarray>
elevtn (y, x) float32 dask.array<chunksize=(240, 360), meta=np.ndarray>
flwdir (y, x) uint8 dask.array<chunksize=(240, 360), meta=np.ndarray>
lndslp (y, x) float32 dask.array<chunksize=(240, 360), meta=np.ndarray>
strord (y, x) uint8 dask.array<chunksize=(240, 360), meta=np.ndarray>
uparea (y, x) float64 dask.array<chunksize=(240, 360), meta=np.ndarray>
Attributes:
category: topography
paper_doi: 10.5194/hess-2020-582
paper_ref: Eilander et al. (2021)
source_license: ODC-By 1.0
source_url: https://zenodo.org/record/5166932#.YVbxJ5pByUk
source_doi: 10.5281/zenodo.5166932
source_version: 1.0
processing_notes: prepared from MERIT Hydro IHU by deriving flow direct...
processing_script: prepare_ldd.ipynb from hydromt_wflow repository