Tip
Example: Working with models in Python#
The main feature of HydroMT is to facilitate the process of building and analyzing spatial geoscientific models with a focus on water system models. It does so by automating the workflow to go from raw data to a complete model instance which is ready to run and to analyse model results once the simulation has finished.
This notebook will explore how to work with HydroMT models in Python.
[1]:
# import hydromt and setup logging
import hydromt
from hydromt.log import setuplog
# other imports
import matplotlib.pyplot as plt
import geopandas as gpd
logger = setuplog("working with models", log_level=10)
2023-02-22 04:42:17,133 - working with models - log - INFO - HydroMT version: 0.7.0
Available models in HydroMT#
To know which models are available within your active environment, you can use global MODELS variable in hydromt
[2]:
# generic model classes
print(f"Generic model classes: {hydromt.MODELS.generic}")
# model classes from external plugin
print(f"Model classes from plugins: {hydromt.MODELS.plugins}")
Generic model classes: ['grid_model', 'lumped_model', 'mesh_model', 'network_model']
Model classes from plugins: []
Here you may only see the generic models grid_model, lumped_model and network_model. There is one more generic model within HydroMT mesh_model which is only available if the additional python mesh dependency xugrid is available in the activated environment.
Model components#
HydroMT defines any model through the model-agnostic Model API based on several general model components and computational unit components, see Model API. Below is a scheme representing the Model API and general model classes available in HydroMT (without any plugin):

Let’s discover how models are constructed within HydroMT and take the example of grid_model. We will first instantiate a GridModel object called mod. The api property helps us discover the available components and their type. You can do the same with any other HydroMT Model class or plugin (give it a try!).
[3]:
mod = hydromt.GridModel()
mod.api
[3]:
{'grid': xarray.core.dataset.Dataset,
'crs': pyproj.crs.crs.CRS,
'config': typing.Dict[str, typing.Any],
'geoms': typing.Dict[str, geopandas.geodataframe.GeoDataFrame],
'maps': typing.Dict[str, typing.Union[xarray.core.dataarray.DataArray, xarray.core.dataset.Dataset]],
'forcing': typing.Dict[str, typing.Union[xarray.core.dataarray.DataArray, xarray.core.dataset.Dataset]],
'region': geopandas.geodataframe.GeoDataFrame,
'results': typing.Dict[str, typing.Union[xarray.core.dataarray.DataArray, xarray.core.dataset.Dataset]],
'states': typing.Dict[str, typing.Union[xarray.core.dataarray.DataArray, xarray.core.dataset.Dataset]]}
Here you see all the general components from the Model class like config, geoms, forcing etc. as well as the GridModel specific computational unit grid. You can see that most components are dictionaries of either xarray DataArray or Datasets or of geopandas GeoDataFrame. For now we are starting from an empty model so all these components will be empty but here is how you can access them:
[4]:
print(type(mod.grid))
mod.grid
<class 'xarray.core.dataset.Dataset'>
[4]:
<xarray.Dataset>
Dimensions: ()
Data variables:
*empty*[5]:
mod.geoms
[5]:
{}
Model setup_* methods#
To fill in our model components with data, HydroMT uses setup_ methods. These methods go from reading input data using the DataAdapter, transforming the data using workflows (e.g. reprojection, deriving model parameters, etc…) and adding the new model data to the right model component. An overview of available setup methods can be found in the API reference for the GridModel, LumpedModel, and MeshModel
Note that these methods for the generic model classes are still quite limited. To get an idea of potential setup_ methods, checkout the model plugins
Let’s have a look at some examples of the setup_ functions to start populating our model like setup_region. This method parses the HydroMT region option to define the geographic region of interest of the model to build and once done adds region into the geoms component. You can check the required arguments in the
docs.
Let’s now setup a region for our model using for example a subbasin for any point in the Piave basin. We first initialize a GridModel instance in writing mode at a model root folder. Data is sourced from the artifact_data catalog.
[6]:
root = "tmp_grid_model_py"
mod = hydromt.GridModel(
root=root,
mode="w",
data_libs=["artifact_data", "data/vito_reclass.yml"],
logger=logger,
)
2023-02-22 04:42:17,241 - working with models - data_catalog - INFO - Reading data catalog artifact_data v0.0.8 from archive
2023-02-22 04:42:17,242 - working with models - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt_data/artifact_data/v0.0.8/data_catalog.yml
2023-02-22 04:42:17,314 - working with models - data_catalog - INFO - Parsing data catalog from data/vito_reclass.yml
2023-02-22 04:42:17,317 - working with models - log - DEBUG - Writing log messages to new file /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py/hydromt.log.
2023-02-22 04:42:17,317 - working with models - model_api - INFO - Initializing grid_model model from hydromt (v0.7.0).
[7]:
xy = [12.2051, 45.8331]
region = {"subbasin": xy, "strord": 7}
mod.setup_region(
region=region,
hydrography_fn="merit_hydro",
basin_index_fn="merit_hydro_index",
)
mod.geoms["region"]
2023-02-22 04:42:17,324 - working with models - basin_mask - DEBUG - Parsed region (kind=subbasin): {'strord': 7, 'xy': [12.2051, 45.8331]}
2023-02-22 04:42:17,326 - working with models - data_catalog - INFO - DataCatalog: Getting merit_hydro RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro/{variable}.tif
2023-02-22 04:42:17,491 - working with models - basin_mask - DEBUG - Getting basin IDs at point locations.
2023-02-22 04:42:21,436 - working with models - basin_mask - INFO - subbasin bbox: [11.7750, 45.8042, 12.7450, 46.6900]
[7]:
| geometry | value | |
|---|---|---|
| 0 | POLYGON ((12.44500 46.69000, 12.45500 46.69000... | 1.0 |
[8]:
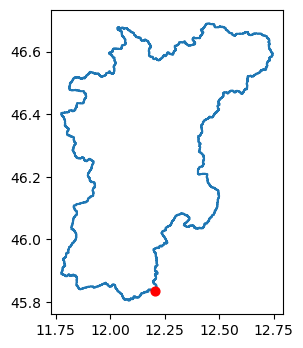
# Plot
fig = plt.figure(figsize=(3, 4))
ax = plt.subplot()
mod.region.boundary.plot(ax=ax)
gdf_xy = gpd.GeoDataFrame(geometry=gpd.points_from_xy(x=[xy[0]], y=[xy[1]]), crs=4326)
gdf_xy.plot(ax=ax, markersize=40, c="red", zorder=2)
[8]:
<Axes: >
Similarly, we can also populate the config component using the setup_config method. For HydroMT config represents the configuration of the model kernel, e.g. the file that would fix your model kernel run settings or list of outputs etc. For most models, this is usually a text file (for example .ini, .toml, .inp formats) that can be ordered in sections. Within HydroMT we then use the dictionary object to represent each header/setting/value.
Let’s populate our config with some simple settings:
[9]:
config = {
"header": {"setting": "value"},
"timers": {"start": "2010-02-05", "end": "2010-02-15"},
}
mod.setup_config(**config)
mod.config
2023-02-22 04:42:21,678 - working with models - model_api - DEBUG - Setting model config options.
[9]:
{'header': {'setting': 'value'},
'timers': {'start': '2010-02-05', 'end': '2010-02-15'}}
We can setup map data using the setup_maps_from_raster and setup_maps_from_raster_reclass methods. Both methods add data to the maps component based on input raster data (RasterDataset type), but the second method additionally reclassifies the input data based on a reclassification table. The maps component gathers any raster input data without any requirements for a specific grid (CRS and resolution). It can contain, for example, direct model input data for models like
Delft3D-FM that will interpolate input data on the fly to the model mesh, or auxiliary data that are not used by the model kernel but can be used by HydroMT to build the model (e.g. a gridded DEM), etc.
For models that require all their input data to be resampled to the exact computation grid (all raster at the same resolution and projection), then the input data would go into the grid component. The corresponding setup_ functions for the grid components are under development.
But back to our example, let’s add both a DEM map from the data source merit_hydro_1k and a manning roughness map based on reclassified landuse data from the vito dataset.
[10]:
mod.setup_maps_from_raster(
raster_fn="merit_hydro_1k",
variables="elevtn",
fill_method=None,
reproject_method=None,
)
_ = mod.setup_maps_from_raster_reclass(
raster_fn="vito",
reclass_table_fn="vito_reclass", # Note: from local data catalog
reclass_variables=["manning"],
)
2023-02-22 04:42:21,686 - working with models - model_api - INFO - Preparing maps data from raster source merit_hydro_1k
2023-02-22 04:42:21,687 - working with models - data_catalog - INFO - DataCatalog: Getting merit_hydro_1k RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro_1k/{variable}.tif
2023-02-22 04:42:21,709 - working with models - rasterdataset - DEBUG - RasterDataset: Clip with geom - [11.775, 45.804, 12.745, 46.690]
2023-02-22 04:42:21,726 - working with models - model_api - INFO - Preparing map data by reclassifying the data in vito based on vito_reclass
2023-02-22 04:42:21,727 - working with models - data_catalog - INFO - DataCatalog: Getting vito RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/vito.tif
2023-02-22 04:42:21,747 - working with models - rasterdataset - DEBUG - RasterDataset: Clip with geom - [11.775, 45.804, 12.745, 46.690]
2023-02-22 04:42:21,770 - working with models - data_catalog - INFO - DataCatalog: Getting vito_reclass DataFrame csv data from /home/runner/work/hydromt/hydromt/docs/_examples/data/vito_reclass.csv
2023-02-22 04:42:21,771 - working with models - dataframe - INFO - DataFrame: Read csv data.
[11]:
# check which maps are read
print(f"model maps: {list(mod.maps.keys())}")
mod.maps["manning"]
model maps: ['elevtn', 'manning']
[11]:
<xarray.DataArray 'manning' (y: 897, x: 981)>
dask.array<transpose, shape=(897, 981), dtype=float32, chunksize=(897, 981), chunktype=numpy.ndarray>
Coordinates:
* x (x) float64 11.77 11.77 11.78 11.78 ... 12.74 12.74 12.75 12.75
* y (y) float64 46.69 46.69 46.69 46.69 ... 45.81 45.8 45.8 45.8
spatial_ref int64 0
mask (y, x) bool False False False False ... False False False False
Attributes:
_FillValue: nan[12]:
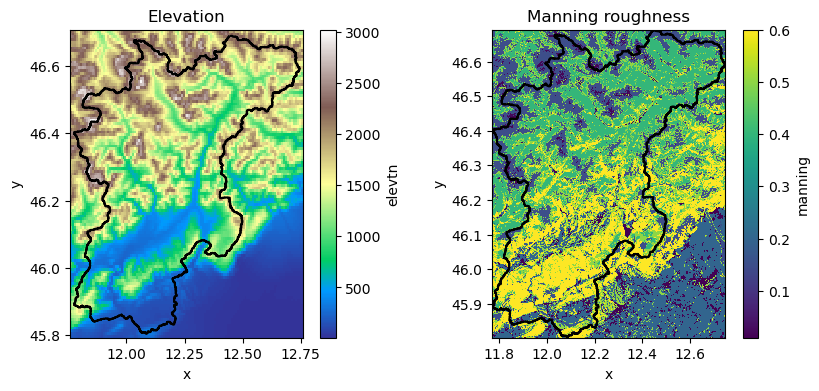
# Plot
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
mod.maps["elevtn"].raster.mask_nodata().plot(ax=axes[0], cmap="terrain")
mod.region.boundary.plot(ax=axes[0], color="k")
gdf_xy = gpd.GeoDataFrame(geometry=gpd.points_from_xy(x=[xy[0]], y=[xy[1]]), crs=4326)
gdf_xy.plot(ax=axes[0], markersize=40, c="red", zorder=2)
axes[0].set_title("Elevation")
mod.maps["manning"].plot(ax=axes[1], cmap="viridis")
mod.region.boundary.plot(ax=axes[1], color="k")
gdf_xy.plot(ax=axes[1], markersize=40, c="red", zorder=2)
axes[1].set_title("Manning roughness")
[12]:
Text(0.5, 1.0, 'Manning roughness')
Model read & write methods#
Once our model is filled up with data, we can then write it down using either the general write method or component specific write_ methods. Similarly, our model can be read back with the general read method or component specific ones.
Let’s now write our model into a model root folder.
[13]:
mod.write(components=["maps", "geoms", "config"])
2023-02-22 04:42:24,006 - working with models - model_api - INFO - Writing model data to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py
2023-02-22 04:42:24,007 - working with models - model_api - DEBUG - Writing file maps/elevtn.nc
2023-02-22 04:42:24,018 - working with models - model_api - DEBUG - Writing file maps/manning.nc
2023-02-22 04:42:24,105 - working with models - model_api - DEBUG - Writing file geoms/region.geojson
2023-02-22 04:42:24,153 - working with models - model_api - INFO - Writing model config to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py/model.ini
[14]:
# print MODEL_ROOT folder
import os
def print_dir(root):
for path, _, files in os.walk(root):
print(path)
for name in files:
if name.endswith(".xml"):
continue
print(f" - {name}")
print_dir(root)
tmp_grid_model_py
- hydromt.log
- model.ini
tmp_grid_model_py/maps
- manning.nc
- elevtn.nc
tmp_grid_model_py/geoms
- region.geojson
And now let’s read it back in a new GridModel instance:
[15]:
mod2 = hydromt.GridModel(root=root, mode="r", logger=logger)
mod2.read(components=["config", "geoms", "maps"])
2023-02-22 04:42:24,167 - working with models - model_api - INFO - Initializing grid_model model from hydromt (v0.7.0).
2023-02-22 04:42:24,168 - working with models - model_api - INFO - Reading model data from /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py
2023-02-22 04:42:24,169 - working with models - model_api - DEBUG - Model config read from /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py/model.ini
2023-02-22 04:42:24,170 - working with models - model_api - DEBUG - Reading model file region.
2023-02-22 04:42:24,189 - working with models - model_api - DEBUG - Reading model file manning.
2023-02-22 04:42:24,195 - working with models - model_api - DEBUG - Reading model file elevtn.
[16]:
# check which maps are read
print(f"model maps: {list(mod2.maps.keys())}")
model maps: ['manning', 'elevtn']
Building / updating a model with python#
Using the same functionalities, it is also possible to build or update a model within python instead of using the command line, using the build and update methods. Let’s see how we could rebuild our previous GridModel with the build method.
First let’s start with writing a HydroMT build configuration (ini-file) with the GridModel (setup) methods we want to use.
[17]:
from hydromt.config import configread
from pprint import pprint
# Read the build configuration
config = configread("grid_model_build.ini")
pprint(
config,
)
{'setup_config': {'header.settings': 'value',
'timers.end': '2010-02-15',
'timers.start': '2010-02-05'},
'setup_maps_from_raster': {'fill_method': None,
'raster_fn': 'merit_hydro_1k',
'reproject_method': None,
'variables': 'elevtn'},
'setup_maps_from_raster_reclass': {'raster_fn': 'vito',
'reclass_table_fn': 'vito_reclass',
'reclass_variables': ['manning']},
'setup_region': {'basin_index_fn': 'merit_hydro_index',
'hydrography_fn': 'merit_hydro'},
'write': {'components': ['config', 'geoms', 'maps']}}
And now let’s build our model:
[18]:
# First we instantiate GridModel with the output folder and use the write mode (build from scratch)
root3 = "tmp_grid_model_py1"
mod3 = hydromt.GridModel(
root=root3,
mode="w",
data_libs=["artifact_data", "data/vito_reclass.yml"],
logger=logger,
)
# Now let's build it with the config file
mod3.build(region=region, opt=config)
2023-02-22 04:42:24,273 - working with models - data_catalog - INFO - Reading data catalog artifact_data v0.0.8 from archive
2023-02-22 04:42:24,275 - working with models - data_catalog - INFO - Parsing data catalog from /home/runner/.hydromt_data/artifact_data/v0.0.8/data_catalog.yml
2023-02-22 04:42:24,344 - working with models - data_catalog - INFO - Parsing data catalog from data/vito_reclass.yml
2023-02-22 04:42:24,347 - working with models - log - DEBUG - Writing log messages to new file /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py1/hydromt.log.
2023-02-22 04:42:24,348 - working with models - model_api - INFO - Initializing grid_model model from hydromt (v0.7.0).
2023-02-22 04:42:24,349 - working with models - model_api - DEBUG - Setting model config options.
2023-02-22 04:42:24,350 - working with models - model_api - INFO - setup_region.region: {'subbasin': [12.2051, 45.8331], 'strord': 7}
2023-02-22 04:42:24,351 - working with models - model_api - INFO - setup_region.hydrography_fn: merit_hydro
2023-02-22 04:42:24,352 - working with models - model_api - INFO - setup_region.basin_index_fn: merit_hydro_index
2023-02-22 04:42:24,353 - working with models - basin_mask - DEBUG - Parsed region (kind=subbasin): {'strord': 7, 'xy': [12.2051, 45.8331]}
2023-02-22 04:42:24,354 - working with models - data_catalog - INFO - DataCatalog: Getting merit_hydro RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro/{variable}.tif
2023-02-22 04:42:24,487 - working with models - basin_mask - DEBUG - Getting basin IDs at point locations.
2023-02-22 04:42:24,874 - working with models - basin_mask - INFO - subbasin bbox: [11.7750, 45.8042, 12.7450, 46.6900]
2023-02-22 04:42:24,915 - working with models - model_api - INFO - setup_maps_from_raster.raster_fn: merit_hydro_1k
2023-02-22 04:42:24,916 - working with models - model_api - INFO - setup_maps_from_raster.variables: elevtn
2023-02-22 04:42:24,917 - working with models - model_api - INFO - setup_maps_from_raster.fill_method: None
2023-02-22 04:42:24,918 - working with models - model_api - INFO - setup_maps_from_raster.name: None
2023-02-22 04:42:24,918 - working with models - model_api - INFO - setup_maps_from_raster.reproject_method: None
2023-02-22 04:42:24,919 - working with models - model_api - INFO - setup_maps_from_raster.split_dataset: True
2023-02-22 04:42:24,919 - working with models - model_api - INFO - Preparing maps data from raster source merit_hydro_1k
2023-02-22 04:42:24,920 - working with models - data_catalog - INFO - DataCatalog: Getting merit_hydro_1k RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/merit_hydro_1k/{variable}.tif
2023-02-22 04:42:24,940 - working with models - rasterdataset - DEBUG - RasterDataset: Clip with geom - [11.775, 45.804, 12.745, 46.690]
2023-02-22 04:42:24,956 - working with models - model_api - INFO - setup_maps_from_raster_reclass.raster_fn: vito
2023-02-22 04:42:24,956 - working with models - model_api - INFO - setup_maps_from_raster_reclass.reclass_table_fn: vito_reclass
2023-02-22 04:42:24,957 - working with models - model_api - INFO - setup_maps_from_raster_reclass.reclass_variables: ['manning']
2023-02-22 04:42:24,957 - working with models - model_api - INFO - setup_maps_from_raster_reclass.variable: None
2023-02-22 04:42:24,958 - working with models - model_api - INFO - setup_maps_from_raster_reclass.fill_method: None
2023-02-22 04:42:24,958 - working with models - model_api - INFO - setup_maps_from_raster_reclass.reproject_method: None
2023-02-22 04:42:24,959 - working with models - model_api - INFO - setup_maps_from_raster_reclass.name: None
2023-02-22 04:42:24,959 - working with models - model_api - INFO - setup_maps_from_raster_reclass.split_dataset: True
2023-02-22 04:42:24,962 - working with models - model_api - INFO - Preparing map data by reclassifying the data in vito based on vito_reclass
2023-02-22 04:42:24,962 - working with models - data_catalog - INFO - DataCatalog: Getting vito RasterDataset raster data from /home/runner/.hydromt_data/artifact_data/v0.0.8/vito.tif
2023-02-22 04:42:24,982 - working with models - rasterdataset - DEBUG - RasterDataset: Clip with geom - [11.775, 45.804, 12.745, 46.690]
2023-02-22 04:42:25,006 - working with models - data_catalog - INFO - DataCatalog: Getting vito_reclass DataFrame csv data from /home/runner/work/hydromt/hydromt/docs/_examples/data/vito_reclass.csv
2023-02-22 04:42:25,006 - working with models - dataframe - INFO - DataFrame: Read csv data.
2023-02-22 04:42:25,015 - working with models - model_api - INFO - write.components: ['config', 'geoms', 'maps']
2023-02-22 04:42:25,015 - working with models - model_api - INFO - Writing model data to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py1
2023-02-22 04:42:25,016 - working with models - model_api - INFO - Writing model config to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py1/model.ini
2023-02-22 04:42:25,017 - working with models - model_api - DEBUG - Writing file geoms/region.geojson
2023-02-22 04:42:25,054 - working with models - model_api - DEBUG - Writing file maps/elevtn.nc
2023-02-22 04:42:25,062 - working with models - model_api - DEBUG - Writing file maps/manning.nc
2023-02-22 04:42:25,158 - working with models - model_api - INFO - Writing model data to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py1
2023-02-22 04:42:25,158 - working with models - model_api - INFO - Writing model config to /home/runner/work/hydromt/hydromt/docs/_examples/tmp_grid_model_py1/model.ini
2023-02-22 04:42:25,160 - working with models - model_grid - DEBUG - No grid data found, skip writing.
2023-02-22 04:42:25,161 - working with models - model_api - DEBUG - Writing file geoms/region.geojson
2023-02-22 04:42:25,201 - working with models - model_api - DEBUG - No forcing data found, skip writing.
2023-02-22 04:42:25,201 - working with models - model_api - DEBUG - No states data found, skip writing.
[19]:
print_dir(root3)
tmp_grid_model_py1
- hydromt.log
- model.ini
tmp_grid_model_py1/maps
- manning.nc
- elevtn.nc
tmp_grid_model_py1/geoms
- region.geojson
And check that the results are similar to our one-by-one setup earlier:
[20]:
mod3.config
[20]:
{'header': {'settings': 'value'},
'timers': {'start': '2010-02-05', 'end': '2010-02-15'}}
[21]:
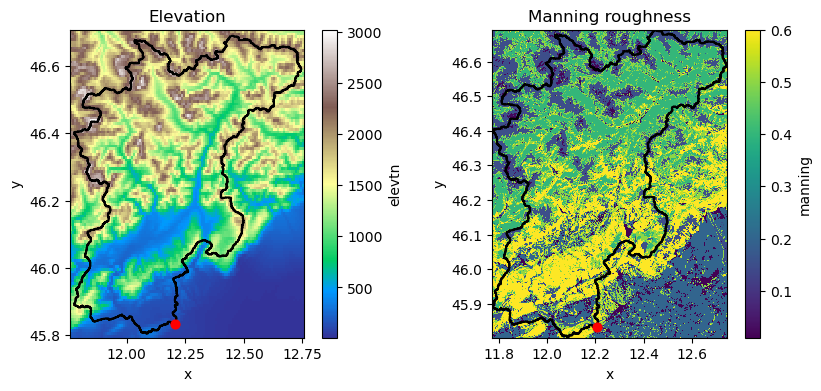
# Plot
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
mod3.maps["elevtn"].raster.mask_nodata().plot(ax=axes[0], cmap="terrain")
mod3.region.boundary.plot(ax=axes[0], color="k")
axes[0].set_title("Elevation")
mod3.maps["manning"].plot(ax=axes[1], cmap="viridis")
mod3.region.boundary.plot(ax=axes[1], color="k")
axes[1].set_title("Manning roughness")
[21]:
Text(0.5, 1.0, 'Manning roughness')